Önceki yazıda bir yorumlayıcının nelerden oluştuğu hakkında bahsetmiştim. Artık kendi dilimizi tasarlamanın zamanı geldi. Bunun için ilk önce bir lexer yapacağız.
Bu yazıda D dilini kullanarak lexerımızı inşa ediyoruz. Neden D dili seçtiğimi ise bir başka yazımda değineceğim. Ben burada kodları Ubuntu 13.10 64 bit üzerinde yazdım. DMD ile derledim. DMD’yi buradan indirebilirsiniz. Eğer ddiline yeni iseniz Ali Çehreli hocamın yazmış olduğu ve şu an Amerika’da bazı üniversitelerde okutulmakta olan kitabından D dilini öğrenebilirsiniz. Kitaba erişmek için ddili.org/ders/d/ sayfasına bakabilirsiniz. D dilinde Merhaba Dünya yazımı okumak için buraya tıklayabilirsiniz.
Öncelikle bir enum oluşturacağız ve içerisine lexerımızda kullanacağımız Token türlerini yazacağız.
enum Type{
nope, identifier, number, string, _true, _false,
//Operators (+,-,*,/,=)
plus, minus, times, divide, equals,
semicolon
}Yukarıda true ve false için başına _ eklemek zorunda kaldık çünkü kullandığımız D dili içerisinde true ve false ları keyword olarak görmesi karışıklık yaratıyor.
Ve şimdi de Token struct’ımızı tanımlıyoruz. Burada oluşturduğum Token içerisinde sadece tür ve değer bilgilerini tutuyorum siz isterseniz satır ve sütun bilgilerini de tutabilirsiniz.
struct Token{
Type type;
string value;
}Fonksiyonumuzu oluşturuyoruz.
Token[] lexit(string code){
Token[] tokens;
auto cp = code.ptr;
auto end = code.ptr + code.length;Kaynak kodu parçalamak için sonlu otomataları kullanıyoruz.
Sonlu otomatalar bir durumdan diğer duruma geçişi esas alır. Sistem 0 başlangıç durumundan başlar. Her durum için bir geçiş kümesi tanımlanır. Örneğin aşağıdaki çizimde ilk durum için a-z geçiş kümesidir. 0 dan 1 e geçiş yapabilmek için a-z harflerinden biri gelmek zorundadır. 1.duruma geçiş yaptığında ise a-z ve 0-9 karakterleri artık geçiş kümemiz oldu ve o karakterler geldiği sürece 1.durumda kalınır.
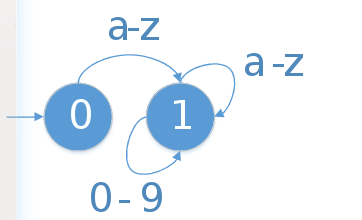
Bizim yapacağımız sistemde bu küme dışında karakter gelirse kimi durumda hata verdireceğiz kimi durumda ise başlangıç durumu yani 0’a geri döneceğiz. Bunu koda dökersek eğer;
while(cp < end){
if(isAlpha(*cp)){//a-z ve A-Z arası harfler gelirse
/* Harf ve sayı olduğu sürece bunları tek tek dizi içerisine atıyoruz */
string tmp;
do{
tmp ~= *cp;
cp++;
} while(cp < end && isAlphaNum(*cp));Burada kodda karakterin a-z ve A-Z arası olup olmadığını std.ascii içerisinde bulunan isAlpha ve isAlphaNum ile kontrol ettik. Şimdi ise tmp de tutulan kelimeyi token dizisine aktarma zamanı.
// Eğer elde edilen kelime bir anahtar kelime ise bunu bir değişken yerine anahtar kelime olarak kayıt ediyor.
if(tmp == "true") tokens ~= Token(Type._true, tmp);
else if(tmp == "false") tokens ~= Token(Type._false, tmp);
else tokens ~= Token(Type.identifier, tmp);Kaynak koddaki boşluk, tab, yeni satır gibi beyaz karakterleri görmezden gelelim.
}else if(isWhite(*cp)){
cp++;Harfleri yakaladığımız gibi rakamları yakalayalım.
}else if(isDigit(*cp)){
//Rakamları yakalıyoruz.
string tmp;
do{
tmp ~= *cp;
cp++;
} while(cp < end && isDigit(*cp));
tokens ~= Token(Type.number, tmp);Bu lexer da stringleri tırnak karakteri ile başlattım ve sonraki tırnak karakterine kadarki bütün karakterleri topluyoruz.
}else if(*cp == '"'){
// "metin" şeklindeki bir stringi elde ediyoruz.
string tmp;
cp++;
do{
tmp ~= *cp;
cp++;
} while(cp < end && *cp!='"'); //Tırnak işareti gelene kadarki bütün karakterleri diziye atıyoruz.
cp++;
tokens ~= Token(Type.string, tmp);Ve aynı şekilde + - gibi özel karakterleri ve yorum satırlarını yakalayacağız.
}else if(*cp == '+'){
tokens ~= Token(Type.plus);
cp++;
}else if(*cp == '-'){
tokens ~= Token(Type.minus);
cp++;
}else if(*cp == '*'){
tokens ~= Token(Type.times);
cp++;
}else if(*cp == '/'){
cp++;
/* "//" şeklindeki yorum satırlarını görmezden gel. */
if(*cp == '/'){
while(cp < end && *cp != 'n'){
cp++;
}
cp++;
}else tokens ~= Token(Type.divide);
}else if(*cp == '='){
tokens ~= Token(Type.equals);
cp++;
}else if(*cp == ';'){
tokens ~= Token(Type.semicolon);
cp++;Son olarak eğer beklenmedik bir karakter geldiyse ekrana hata mesajı fırlatacağız.
}else{
throw new Exception("Beklenmeyen karakter: %s".format(*cp));
}
}
return tokens;
}Evet artık Lexerımız hazır sadece kendisine gönderilecek olan kodu bekliyor. Ben deneme amaçlı aşağıdaki kodu yazdım.
auto code = "
deneme = 1 + 2 // bu bir yorum alanı
ikincidegisken = \"deneme\"
";
Lexer lex = new Lexer();
auto tokens = lex.lexit(code);
writefln("Kod:\n%s\nLexer Çıktısı:\n",code);
foreach(token;tokens){
writeln(token);
}Aldığım çıktı ise:
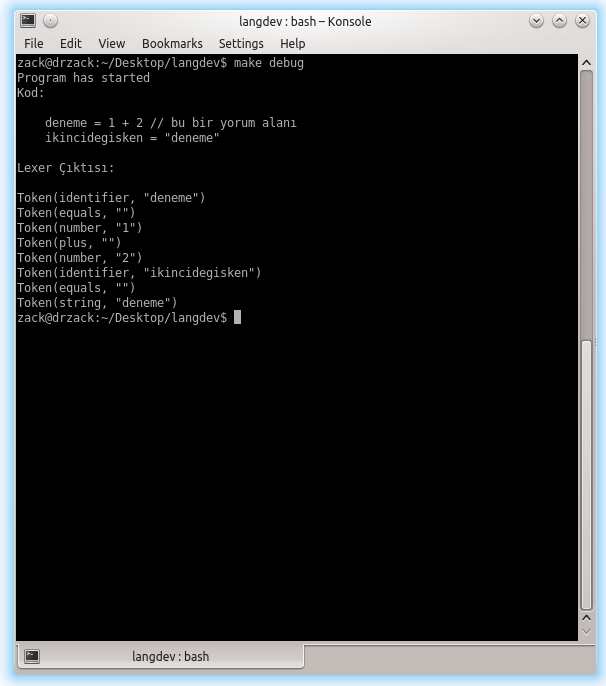
Projeyi indirmek için: Make Your Own Language - 1
isWhite, isDigit gibi fonksiyonların bulunduğu std.ascii kütüphanesi